Machine Data Science With Event Hubs & CrateDB
A Machine Learning Pipeline Using EventHubs, CrateDB, and Jupyter

This post is the result of a CSE engagement with Crate.io, where I used to work before Microsoft
Convenient data science, wouldn’t that be great?
When creating or buying an IoT (Internet of Things) type solution, it comes without any further ways to actually make something out of the data - this is left to you, the user. Where to put the data and store only the relevant bits? How can this be made an easy to use and easy to manage solution for your data scientists?
This engagement was about that: Microsoft and CrateDB worked together to connect CrateDB to your stream data from Azure. Keep reading to find out more.
Putting Stream Data To Work
Microsoft’s Azure platform offers a wealth of different messaging services, starting from a reliable and feature-rich Azure ServiceBus to the lightweight and high-throughput Azure Event Hubs. Since CrateDB is a database for things data, it’s a perfect fit for ingesting data out of the specialized Azure IoT Hub - which offers an Event Hubs endpoint.
Event Hubs are built for large scale messaging and handling streams of data - something that IoT devices are often good at producing. In fact, many users will use the IoT Hub as a management endpoint for devices, configurations, device commands etc. but forward the incoming data stream into an Azure Function for further enrichment or transformation.
Once that’s done, the processed data is captured in a database for further use - analytics or dashboards are great examples for combining this live data stream with historical data.
A Database Consumer
CrateDB is a great fit for this kind of database. It offers SQL capabilities and with its distributed nature will be able to work with tens of thousands of inserts per second - something I built many times for customers in the past.
However, it’s time to go one step further: ingesting streaming data. In a joint effort, we added prototypical ingestion support for Event Hubs. As of this writing, this code lives in a branch on the official CrateDB repository - you’ll have to build it from there.
Consuming a stream of data into a database, how can that help your IoT deployment? In short: data science.
Sensor data can grow quickly and as long as there is no incident, does not provide a lot of immediate business value. If this data is used to create models that infer details about the device the sensor is monitoring.
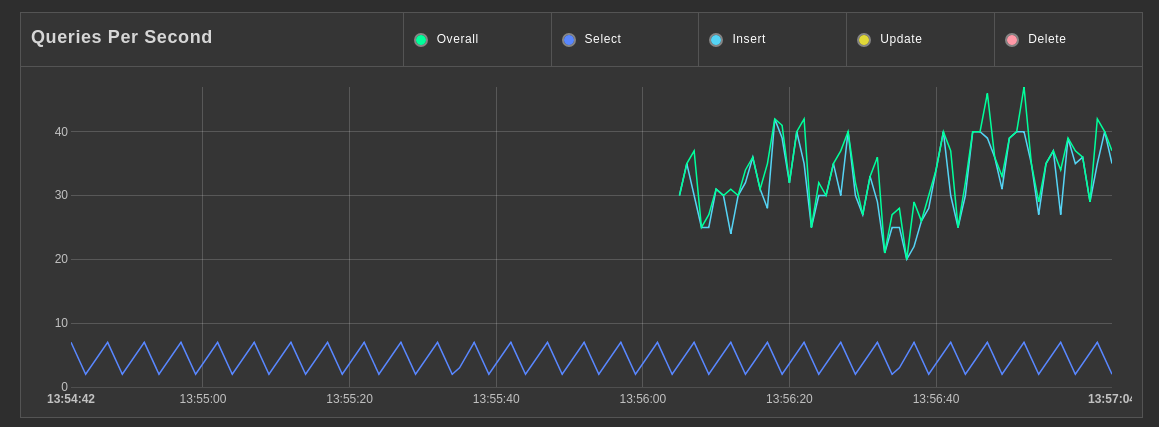
Let the streaming begin!
A Data Science Pipeline
Data can be useful in a range of ways, predictive maintenance or data mining for product reasons are the most common goals that organizations want to implement.
Set Up
If you have a Microsoft Azure Account (it’s free!), it’s easy to set everything up and for CrateDB to connect to stuff. The required ingredients are:
- CrateDB Enterprise with Event Hubs consumer (from here)
- An Event Hub endpoint, either directly or via an IoTHub
- Python, or Jupyter within reach of a CrateDB endpoint (locally or https://notebooks.azure.com with a public CrateDB IP)
Azure Resources
Let’s start off with setting up the Azure resources. First a resource group is required, since it’s a management tool to group together Azure resources:
Note: this requires the Azure CLI (v2). Get it here or use the terminal built into the portal
$ az group create -n "cratedb-iothub" --location "westeurope"
This is going to be the group we collect everything in, the IoT Hub…
$ az iot hub create -g "cratedb-iothub" -n "enginehub"
… and the storage account. This account is using the newer v2 storage, enabling a bunch of features and APIs. V1 storage is fine too.
A note on the storage requirements: for the Event Hubs receiver to coordinate partition assignments (i.e. which reader reads from which partition) and save the message that it read last, it stores this information on an Azure storage account. This has two major advantages:
- No message gets lost when another node takes over reading from the Event Hub
- Coordination of which node works on which partition is easily managed
On top of that, Event Hubs have a capture function that store unread message on a persistent disk for a short amount of time.
Here are the commands to create a storage account and a blob container for everything:
$ az storage account create -n x5ffeventstore -g "cratedb-iothub" --kind StorageV2 --sku Standard_LRS
$ az storage account show-connection-string -g cratedb-iothub -n x5ffeventstore
$ az storage container create -n events --connection-string "<the connection string from above>"
Lastly, the required parameters should be acquired using the CLI commands:
$ az iot hub show -n "enginehub" -g "cratedb-iothub" --query "properties.eventHubEndpoints.events"
$ az storage account show-connection-string -g cratedb-iothub -n x5ffeventstore
With these bits set up, let’s connect the next piece: CrateDB.
Build CrateDB
Start by cloning the git repository custom version of the branch. Then update the submodules, and after that, check out the branch azure-IoT-hub-hackday:
$ git clone https://github.com/crate/crate.git
...
$ cd crate/
$ git submodule update --init
...
$ git checkout azure-IoT-hub-hackday
Finally, start the build process by issuing this command from within the crate directory. This will take a while so take a break and get some fresh air maybe.
$ ./gradlew installDist
...
Once done, you can find the binary build in the app/build/install subdirectory, along with a default config file etc.
$ cd app/build/install
$ bin/crate # to start
Before running the database it would be wise to configure it properly beforehand 😄.
CrateDB Config
For CrateDB to be able to connect to an endpoint, a few configuration items have to be set. In fact, every property except the consumer group name (unless you want something different than the default) is necessary for CrateDB to work.
Here are the options in crate.yml:
######################### AZURE EVENT HUBS SUPPORT ###########################
# Enables the Azure Event Hub ingestion source on this node.
# Default: false
# Runtime: no
ingestion.event_hub.enabled: true
# The connection string of the Event Hub to receive from.
# Runtime: no
ingestion.event_hub.connectionString: "Endpoint=sb://<random-string>.servicebus.windows.net/;SharedAccessKeyName=iothubowner;SharedAccessKey=..."
# The connection string for the Azure Storage account to use for
# persisting leases and checkpoints.
# Runtime: no
ingestion.event_hub.storageConnectionString: "DefaultEndpointsProtocol=https;EndpointSuffix=core.windows.net;AccountName=x5ffeventstore;AccountKey=..."
# The Azure Storage container name for use by the reciever’s lease and checkpoint manager.
# Runtime: no
ingestion.event_hub.storageContainerName: "events"
# The name of the Azure Event Hub to recieve events from.
# Runtime: no
ingestion.event_hub.eventHubName: "iothub-ehub-enginehub-736057-f3736071df"
# The name of the consumer group to use when recieving from the Azure Event Hub.
# Default: $Default
# Runtime: no
#ingestion.event_hub.consumerGroupName
With these options set, the database should be able to connect to the IoT Hub endpoint. It takes care of everything: distribution and redistribution, keeping track of what’s been read, etc - across multiple nodes! In fact the database will tell you about these things when booting.
Try it in order to make sure all the credentials are properly in place, then your logging output should look something like this (the number of partitions may vary):
$ bin/crate
[2018-09-06T17:13:43,996][INFO ][o.e.n.Node ] [Mont Néry] initializing ...
[2018-09-06T17:13:44,170][INFO ][o.e.e.NodeEnvironment ] [Mont Néry] using [1] data paths, mounts [[/home (/dev/mapper/fedora_localhost--live-home)]], net usable_space [155gb], net total_space [410.4gb], types [ext4]
[2018-09-06T17:13:44,171][INFO ][o.e.e.NodeEnvironment ] [Mont Néry] heap size [3.8gb], compressed ordinary object pointers [true]
[2018-09-06T17:13:44,539][INFO ][i.c.plugin ] [Mont Néry] plugins loaded: [lang-js, hyperLogLog, jmx-monitoring]
...
[2018-09-06T17:13:51,144][INFO ][i.c.i.p.EventProcessor ] Partition 0 is opening on iothub-ehub-enginehub-736057-f3736071df (consumer group: $Default)
[2018-09-06T17:13:51,431][INFO ][i.c.i.p.EventProcessor ] Partition 1 is opening on iothub-ehub-enginehub-736057-f3736071df (consumer group: $Default)
Once that’s done, we can move on and create devices, ingestion rules, and more.
Production Users Beware
For security reasons you should never use the iothubowner key in external applications, since this key can also manage devices (and therefore add and delete them). Read up on IoT Hub security before deploying to production!
Create Devices, Rules, And Value
IoT Hub on Azure is a way to manage many devices, device settings, and their keys alongside the messaging infrastructure. Consequently, any device that wants to send anything into the cloud needs to be provisioned first.
After installing the CLI extension for IoT Hub, there is another command in the Azure CLI that lets you create devices with an id specified in with the -d flag. In order to connect as this device, a connection string is required, so the second command fetches that right away.
$ az iot hub device-identity create -d device-1 --login "<connection-string>"
{
"authentication": {
...
},
"capabilities": {
"iotEdge": false
},
"cloudToDeviceMessageCount": 0,
"connectionState": "Disconnected",
"connectionStateUpdatedTime": "0001-01-01T00:00:00",
"deviceId": "device-1",
"etag": "MTEyMzg2MTIy",
"generationId": "636719226678552445",
"lastActivityTime": "0001-01-01T00:00:00",
"status": "enabled",
"statusReason": null,
"statusUpdatedTime": "0001-01-01T00:00:00"
}
$ # Write down this connection string:
$ az iot hub device-identity show-connection-string -d device-1 --login "<connection-string>"
{
"cs": "HostName=enginehub.azure-devices.net;DeviceId=device-1;SharedAccessKey=..."
}
Once that is done, it’s time to think about how the data stream is going to be saved within CrateDB. Since it’s a database that operates on relations, a table is required!
Create one with the familiar CREATE TABLE syntax then add an “ingestion rule” that maps events from the Event Hub onto the table. Be aware that the table has to have certain columns in order to be valid for event hub data (partition_context, event_metadata, ts, and payload in the statement below).
CREATE TABLE enginehub_events (
"partition_context" OBJECT(DYNAMIC),
"event_metadata" OBJECT(DYNAMIC),
"ts" TIMESTAMP,
"payload" STRING,
"unit #" AS split("payload", ' ')['0']::INTEGER,
"cycle #" AS split("payload", ' ')['1']::INTEGER,
"setting 1" AS split("payload", ' ')['2']::FLOAT,
"setting 2" AS split("payload", ' ')['3']::FLOAT,
"setting 3" AS split("payload", ' ')['4']::FLOAT,
"sensor 1" AS split("payload", ' ')['5']::FLOAT,
"sensor 2" AS split("payload", ' ')['6']::FLOAT,
"sensor 3" AS split("payload", ' ')['7']::FLOAT,
"sensor 4" AS split("payload", ' ')['8']::FLOAT,
"sensor 5" AS split("payload", ' ')['9']::FLOAT,
"sensor 6" AS split("payload", ' ')['10']::FLOAT,
"sensor 7" AS split("payload", ' ')['11']::FLOAT,
"sensor 8" AS split("payload", ' ')['12']::FLOAT,
"sensor 9" AS split("payload", ' ')['13']::FLOAT,
"sensor 10" AS split("payload", ' ')['14']::FLOAT,
"sensor 11" AS split("payload", ' ')['15']::FLOAT,
"sensor 12" AS split("payload", ' ')['16']::FLOAT,
"sensor 13" AS split("payload", ' ')['17']::FLOAT,
"sensor 14" AS split("payload", ' ')['18']::FLOAT,
"sensor 15" AS split("payload", ' ')['19']::FLOAT,
"sensor 16" AS split("payload", ' ')['20']::FLOAT,
"sensor 17" AS split("payload", ' ')['21']::FLOAT,
"sensor 18" AS split("payload", ' ')['22']::FLOAT,
"sensor 19" AS split("payload", ' ')['23']::FLOAT,
"sensor 20" AS split("payload", ' ')['24']::FLOAT,
"sensor 21" AS split("payload", ' ')['25']::FLOAT
);
The ingestion rule looks as follows:
CREATE INGEST RULE enginehub_events ON event_hub
INTO enginehub_events;
You might ask: what is this split() thing and why is this code so redundant? There are two functions in play that I absolutely love at CrateDB:
The former denotes a way for columns to be the result of a function on insert and update. This is really powerful and as shown here lets us populate columns with the appropriate data type with a low overhead on insert. In fact, the values are stored on disk once generated!
The other cool feature, user defined functions, are the ability to use JavaScript to extend scalar functions in CrateDB. This way, the missing split() function for strings can easily be added just like this:
CREATE OR REPLACE FUNCTION split(s string, split_chars string)
RETURNS object
LANGUAGE JAVASCRIPT
AS 'function split(s, split_chars) {
return s.trim().split(split_chars).map(function(e) { return e.trim();});
}';
Once the data is structured and has been added to CrateDB, we have the full power of SQL to do data preprocessing, dicing, and slicing!
Pretending to be An Engine
Did you spot what data this is? It’s NASA’s commerical modular aero-propulsion system simulations (C-MAPSS), i.e. simulated values for turbofan engines, a typical use case for CrateDB and a perfect fit for doing predictive maintenance, since this data is mostly from failing engines!
The data itself consists of 21 sensor readings, three important settings, identified by unit # and cycles (basically the time). Read more here.
For testing the CrateDB - Event Hubs Integration, I created a small JavaScript implementation that sends data to the IoT Hub (the default routing takes care of moving the stream through). Find the code on GitHub.
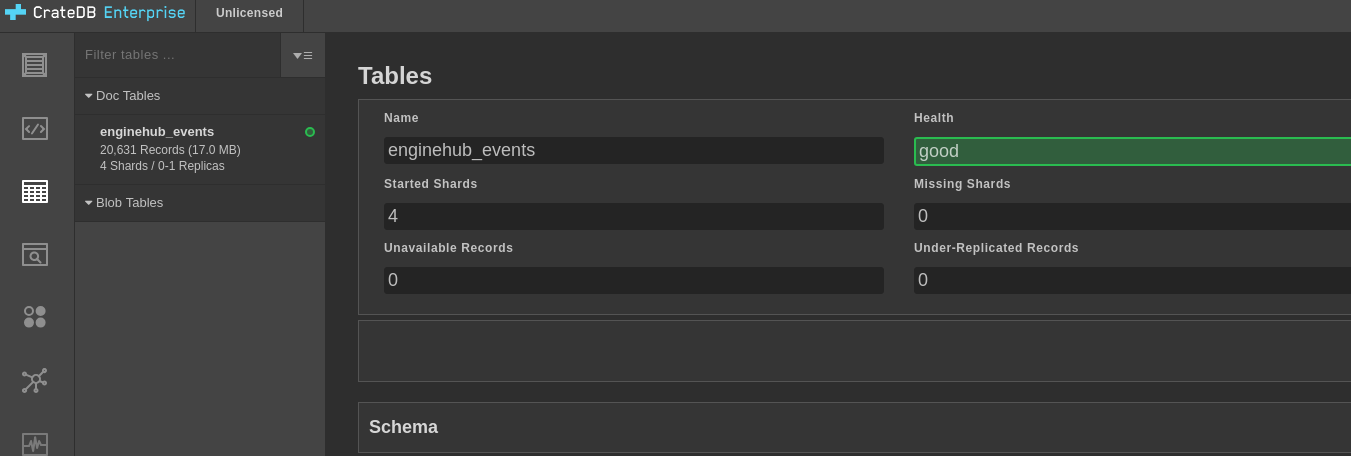
After running client.js for a while.
By running the client.js, rows of training data from the C-MAPSS will be sent to IoT hub for ingestion, which we can then use and explore using a Jupyter Notebook.
Data Exploration And LSTM Readiness
CrateDB’s Python client is SQLAlchemy compatible which makes it easy to query data from within pandas, a famous data analysis library. This is great for exploring the data, preparing it for LSTMs, or cleaning it up. Just like we are used to in SQL databases, views can be a good way to show only a subset of data.
In order to prepare the data for an LSTM, we would need a few preceding periods for each line to have in the data set, so the neural network can predict current values from that. This table roughly shows what the data should look like ideally:
| unit # | sensor 1 (t-2) | sensor 1 (t-1) | sensor 1(t) |
|---|---|---|---|
| 1 | 7 | 7 | 7 |
| 2 | 8 | 5 | 2 |
| 3 | 4 | 3 | 3 |
With CrateDB’s fantastic join feature, that can be as easy as:
select a."unit #", a."sensor 4", b."sensor 4" as "sensor 4 (t - 1)"
from enginehub_events a
inner join enginehub_events b
on a."unit #" = b."unit #"
and b."cycle #" = (a."cycle #" - 1)
where a."unit #" = 1; -- an optional filter .
Using matplotlib and pandas, plotting the data becomes really easy:
import pandas as pd
from matplotlib import pyplot as plt
from crate.client import connect
connection = connect("localhost:4200")
query = """select a."unit #", a."sensor 4", b."sensor 4" as "sensor 4 (t - 1)"
from enginehub_events a
inner join enginehub_events b
on a."unit #" = b."unit #"
and b."cycle #" = (a."cycle #" - 1)
where a."unit #" = 1;
"""
data = pd.read_sql_query(query, connection)
plt.figure(figsize=(21,5))
plt.title("Sensor 4")
plt.plot(data["sensor 4"])
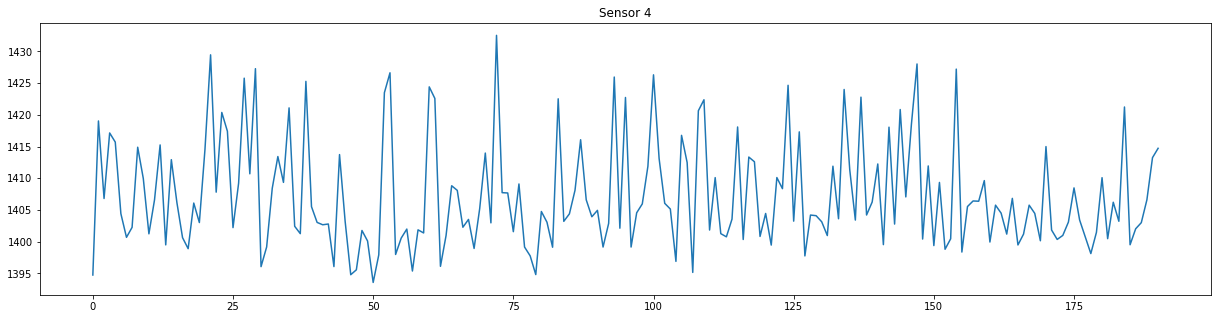
Sensor 4 time series
This is a breeze compared to working with untangling the relationships between the technologies!
Stay Tuned
The CMAPSS dataset is really interesting and a great place to start learning different techniques of working with sequential data. These techniques include LSTMs, GRUs, and sliding windows and moving averages, but that’s reserved for the next post.
Check out the GitHub repository for actual code.
Get a notification for the follow up in your RSS reader (like feedly), or on Twitter if you follow me there.
Thank you for your time!






