4 Lessons to Understand AzureML Data Pipelines
A page of the missing manual
The AzureML SDK is Microsoft’s machine learning support framework that comes with several examples, docs, best practices etc. However, working on a simple ETL-type scenario, I learned a few key insights that I wanted to share. First, let’s clarify what AzureML Services are.
What is AzureML?
The concept of the AzureML framework is great. It supports all areas of the machine learning cycle and it’s generic, which means it works with anything that you are willing to call machine learning. The magnitude is actually noteworthy: distributed data preparation, distributed training that works locally as well as remotely, model management, centralized metrics storage and output tracking, and automation for all of the above!
There is even some documentation and sample notebooks.
On paper, this is great - but what about real use?
Moving data in Real Life
I started with something simple:
Prepare the data by running a Python script on an Excel input file on blob storage and output the resulting parquet file on blob storage for further processing.
This sounded like a great use case for a pipeline with a PythonScriptStep that has the input and output Datastores available. Inside the script I thought the steps were just as simple:
Go buy Christmas presents- Read from one place
- Write to another place
One important thing to bear in mind is that once you use AzureML with remote compute, you are using a distributed system, which means that the complexity of a remote environment and some deeper understanding is required - especially with respect to data movement. So how to solve this problem?
Getting started
The starting point was one of the many examples, namely this one.
I picked a task similar to mine:
extractStep = PythonScriptStep(
script_name="extract.py", # script to run
arguments=[
"--input_extract", blob_input_data,
"--output_extract", processed_data1
],
inputs=[ blob_input_data ], # a DataReference object
outputs=[ processed_data1 ], # a PipelineData object
compute_target=aml_compute, # a remote compute target
source_directory=source_directory) # directory for training code
The in-/output definitions in the notebook look straightforward. Here’s a summary:
blob_input_data = DataReference(
datastore=def_blob_store, # the default data store
data_reference_name="test_data", # not really required
path_on_datastore="") # "" is the root directory of the Datastore, can be a file too
# [ ... ]
processed_data1 = PipelineData("processed_data1", datastore=def_blob_store)
Great, having the inputs and outputs defined (and the paths passed in via arguments), I looked at what the script extract.py does:
# [...]
parser = argparse.ArgumentParser("extract")
parser.add_argument("--input_extract", type=str, help="input_extract data")
parser.add_argument("--output_extract", type=str, help="output_extract directory")
args = parser.parse_args()
# [ ... ]
if not (args.output_extract is None):
os.makedirs(args.output_extract, exist_ok=True) # <- this line turned out to be VERY important
print("%s created" % args.output_extract) # do stuff here
With a scaffold available, I was finally able to run some code … only to see it not working. Since I knew the example script must be right, I had to start digging and when I re-emerged days later witha a solution it definitely gave me a deeper understanding of what AMLS is trying to do. The first step was - as is common - to instrument the code.
What is actually passed into the script?
While I specified types for arguments, inputs, and outputs I didn’t think that there typed representation would actually make it into the training script with all the methods, properties, etc. intact. Bearing in mind the fact that the orchestration and training are probably different machines on Azure, I wasked myself: what is my script going to receive? Printing the arguments and checking the driver logs gave me something equivalent to this:
>>> parser = argparse.ArgumentParser("train")
>>> parser.add_argument("--output_extract", type=str)
>>> parser.add_argument("--input_extract", type=str)
>>> args = parser.parse_args()
>>> print("Arguments", args)
Arguments Namespace(input_extract='/mnt/batch/tasks/shared/LS_root/jobs/amls/azureml/76da247c-3586-43eb-878d-11f23868dd75/mounts/mystorageaccount', output_extract='/mnt/batch/tasks/shared/LS_root/jobs/amls/azureml/76da2a7c-3586-43eb-878d-11a2f86aa875/mounts/workspaceblobstore/azureml/07e2129a-a331-4d05-8df7-58ef3935ec93/processed_data1')
Looking at the values of the arguments, it looks like paths where the data should be/go is passed in. Should? The output_extract argument’s path contains a directory that may not actually exist (yet) - named after the name parameter in the PipelineData object. The first thing that I learned:
1. Be sure to always call os.makedirs(path, exist=True) on the path before creating files.
After that, use any Python way to create files:
os.makedirs(args.output_mount, exist_ok=True)
df.to_parquet(os.path.join(args.output_extract, "myfile.parquet"), index=False)
With small addition I was able to write to the Datastore that I had passed in. But where did the data end up?
Where is my data?
In my initial idea I wanted to register a Dataset. This requires an accessible storage location so any downstream users of that Dataset are able to seamlessly use it. So where on Azure did I write the data to? After some tinkering it slowly became clear:
If the Datastore is a storage account, it has to be registered with a container name. Inside this blob container (“mlops” in the image below) the framework creates a directory “azureml”, followed by a UUID (not the run id though), and the name specified in the PipelineData object that was passed in.
2. The PipelineData output follows this directory structure inside the Datastore: /azureml/<UUID>/<PipelineData-name>.
Compare the “Location” value in the following screenshot of the account with the code example in the previous section:
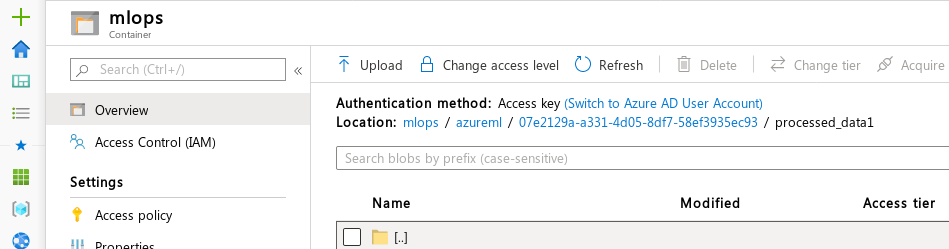
In other words, /azureml/07e2129a-a331-4d05-8df7-58ef3935ec93/processed_data1 was where the data actually sat on the storage account and I had to use pathlib to extract parts:
path = pathlib.Path(args.output_extract)
ds_path = os.path.join(*path.parts[-3:])
Many examples are based on the idea that a Datastore is simply available, how do we get a specific one from inside the Run though?
Accessing a Datastore
In order to comfortably access to the Datastore that is associated with the PipelineData (i.e. the path) from within the script, I had to pass in the name of the Datastore as an argument. The following snippet is a result of the code I used in the end and the structure is as follows: first I get the workspace, use it to fetch the Datastore by name:
run = Run.get_context()
exp = run.experiment
ws = run.experiment.workspace
ds = Datastore.get(ws, args.output_datastore) # this is now the Datastore object (required for a Dataset, for example)
path = pathlib.Path(args.output_extract)
ds_path = os.path.join(*path.parts[-3:]) # this holds now the path to the output directory on "ds"
3. To access the Datastore of a given path, pass the name to the script, and use the API to get an object.
This Datastore object is useful in creating Datasets which is a very useful tool to pass data around your ML system. This will be covered in another blog post.
The problem with AuthenticationFailed
When I followed the previous snippet and used ds.upload() instead of mounts, an AuthenticationFailed error was the result:
Traceback (most recent call last):
File "code/training/select-data.py", line 134, in <module>
ds.upload_files([file_path for name, (df, file_path) in mapping.items()])
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/data/azure_storage_datastore.py", line 738, in upload_files
lambda target, source: lambda: self.blob_service.create_blob_from_path(self.container_name, target, source)
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/data/azure_storage_datastore.py", line 281, in _start_upload_task
if exists(target_file_path):
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/data/azure_storage_datastore.py", line 736, in <lambda>
lambda target_file_path: self.blob_service.exists(self.container_name, target_file_path),
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/blob/baseblobservice.py", line 1632, in exists
_dont_fail_not_exist(ex)
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/common/_error.py", line 97, in _dont_fail_not_exist
raise error
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/blob/baseblobservice.py", line 1628, in exists
self._perform_request(request, expected_errors=expected_errors)
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/common/storageclient.py", line 381, in _perform_request
raise ex
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/common/storageclient.py", line 306, in _perform_request
raise ex
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/common/storageclient.py", line 292, in _perform_request
HTTPError(response.status, response.message, response.headers, response.body))
File "/azureml-envs/azureml_2e1d9ce4998f82687e4497b2f43de6fe/lib/python3.6/site-packages/azureml/_vendor/azure_storage/common/_error.py", line 115, in _http_error_handler
raise ex
azure.common.AzureHttpError: Server failed to authenticate the request. Make sure the value of Authorization header is formed correctly including the signature. ErrorCode: AuthenticationFailed
4. Use mounted options whenever possible.
I ran into this issue and couldn’t solve it with conventional means. I ended up using mount options wherever possible.
TL; DR: Using Azure Machine Learning services
If you are just here for the code, here it is:
# filename "train.py"
parser = argparse.ArgumentParser("train")
parser.add_argument("--output_extract", type=str)
parser.add_argument("--input_extract", type=str)
parser.add_argument("--output_datastore", type=str)
args = parser.parse_args()
run = Run.get_context()
exp = run.experiment
ws = run.experiment.workspace
os.makedirs(args.output_extract, exist_ok=True)
df.to_parquet(os.path.join(args.output_extract, "myfile.parquet"), index=False)
ds = Datastore.get(ws, args.output_datastore)
path = pathlib.Path(args.output_extract)
ds_path = os.path.join(*path.parts[-3:])
print("Uploaded your file to", args.output_datastore, "at path:", ds_path)
Together with the pipeline configuration the script executes exactly what I wanted:
- Load data from an input storage account
- Run some processing on the data
- Put the output on another storage account
Here are the essentials for configuring the step and pipeline:
aml_workspace = Workspace(subscription_id, "my-resource-group", "workspace-name")
aml_compute = ... # get remote compute from somewhere
ds = aml_workspace.datastores["my_data_store"]
blob_input_data = DataReference( datastore=ds, path_on_datastore="")
processed_data1 = PipelineData("processed_data1", datastore=ds)
extract_step = PythonScriptStep(
script_name="train.py",
arguments=[
"--input_extract", blob_input_data,
"--output_extract", processed_data1
"--output_datastore", "my_data_store"
],
inputs=[ blob_input_data ],
outputs=[ processed_data1 ],
compute_target=aml_compute,
source_directory=".")
train_pipeline = Pipeline(workspace=aml_workspace, steps=[extract_step])
# make sure stuff works
train_pipeline.validate()
# your pipeline will show up on ml.azure.com
train_pipeline.publish(name="My-Pipeline")
# start a pipeline run
train_pipeline.submit()
Obviously, pipelines can have many more steps and do much more complex things and the snippet above represents a starting point. As my ML projects continue, I’ll publish more posts on the topic of getting AzureML to do what you want.
During my search I also found out about what happens in the background. Read on if you are interested.
Background stuff (that most won’t care about)
AzureML builds a Docker container with your dependencies that mounts and runs the Python script from a storage account it creates. This allows for seamless execution regardless of the machine and an easy way to use data storage together with the code. Just like any other containerized environment, the script can just operate on the file system without having to care about actual locations.
Consequently, I observed:
- The source code is downloaded on the AMLS workspace’s blob storage under a UUID that is not the run id.
- This is also the default Datastore
- Likely this is also where a Run uploads any data with Run.upload() invoked
- The folder structure is created in every Datastore using arbitrary UUIDs in an
azuremldirectory
Output paths are PipelineData objects (instead of DataReference objects). Here too I made some observations:
- Just like any other Docker volume, the paths get mounted by default
- The parameter contains the path
- However, name parameter is also a directory name that doesn’t get created automatically.
Ultimately, it looks like the pipeline UI is responsible for my confusion. Thinking in terms of lines to be dragged from a “DataReference” to a ScriptStep that outputs data into a Pipeline to whatever follows it made a lot more sense in the end.
By understanding these facts, I was able to get to the problems and their solutions much quicker, which made me more productive and happier 😁.
Never miss any of my posts and follow me on Twitter, or even better, add the RSS feed to your reader!






