Announcing rust-cratedb 1.0
CrateDB's Rust driver reaches 1.0!

With the 1.0 release of my Rust driver for CrateDB, I decided to share how the driver works as well as document some of the decisions around its creation. Check out the repository for the driver on Github.
CrateDB
CrateDB is a distributed SQL database and BLOB store that is particularly well suited for anything that generates a large volume of data and requires analysis - sensor data being a prime example. The interface is simple: by offering a RESTful endpoint that JSON-encodes SQL statements and data, a driver for CrateDB is only little more than a wrapper around a HTTP client that takes care of encoding and error handling. For a less text-based approach, it’s also possible to connect via the Postgres Wire protocol to achieve better efficiency and make use of streaming.
Architecture
Designing a driver API from scratch is hard - and without a common interface proposal (e.g. like JPA, or .NET’s datasource), switching database drivers will require rewriting a good part of the application. That’s why rust-cratedb looked a lot at rust-postgres to create a familiar API and the internal design has been structured in a way that the outward-facing SQL interface is a trait. Thus by implementing the trait on a different backend will enable better maintainability and portability later on. This is a rough overview over the architecture:
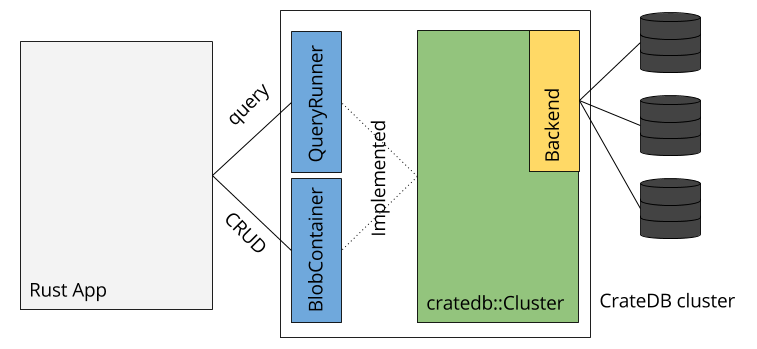
Ultimately the required imports are minimal:
extern crate cratedb;
use cratedb::{Cluster, NoParams};
use cratedb::sql::QueryRunner; // SQL query trait
use cratedb::blob::{BlobContainer, BlobRef}; // BLOB container trait
use cratedb::row::ByIndex; // index-based access to the result columns
Backend
The backend is where the magic happens, and it takes a string payload and a few parameters to send the request off to a cluster. This cluster (i.e. the Cluster class) represents multiple CrateDB nodes that will be ’load balanced’ whenever a query is executed. In fact, these nodes are chosen at random:
fn get_endpoint(&self, endpoint_type: EndpointType)
-> Option<String> {
if !self.nodes.is_empty() {
let node = random::<usize>() % self.nodes.len();
let host = self.nodes[node].as_str();
let t = match endpoint_type {
EndpointType::SQL => "_sql",
EndpointType::Blob => "_blobs",
};
Some(format!("{}{}", host, t))
} else {
None
}
}
This function selects a node and uses its address to create an endpoint for the driver to use and passes the address on to the Backend implementation attached to the Cluster. By default this is HTTP-based but it could easily change as long as this trait is implemented:
pub trait Backend {
fn execute(&self,
to: Option<String>,
payload: String)
-> Result<(BackendResult, String), BackendError>;
fn upload_blob(&self,
to: Option<String>,
bucket: &str,
sha1: &[u8],
f: &mut Read)
-> Result<BackendResult, BackendError>;
fn delete_blob(&self,
to: Option<String>,
bucket: &str,
sha1: &[u8])
-> Result<BackendResult, BackendError>;
fn fetch_blob(&self,
to: Option<String>,
bucket: &str,
sha1: &[u8])
-> Result<(BackendResult, Box<Read>), BackendError>;
}
This interface notably uses string as the payload data type, so any encoding/decoding happens beforehand to keep dependencies separated into their layers. Upon entering the function, a client is created (in the case of the HTTPBackend it’s a HTTPClientFactory) depending on the required encryption mode (and for maintainability):
fn delete_blob(&self,
to: Option<String>,
bucket: &str,
sha1: &[u8])
-> Result<BackendResult, BackendError> {
if let Ok(to) = make_blob_url(to, bucket, sha1) {
let client =
self.client_factory.client(to.scheme().to_string());
client
.delete(to)
.send()
.map(|r| parse_status(&r.status))
.map_err(BackendError::from_transport)
} else {
Err(BackendError::new("Invalid blob url".to_string()))
}
}
As a consequence, each time a request is issued a new object is created and disposed of after the execution. For HTTP, these clients are basically hyper::client::Client objects, however in later implementations this might change.
SQL & BLOB
Using traits in Rust for separating concerns create very neat APIs that can easily be extended later on. Consequently it made a lot of sense to transition to two distinct interfaces when adding BLOB support, one for each domain: SQL and BLOBs.
The formerly single SQL interface was renamed to QueryRunner, which - I admit - is not the best name, but it works for now. However the functions it provided stayed the same:
pub trait QueryRunner {
fn query<SQL, S>(&self, sql: SQL, params: Option<Box<S>>)
-> Result<(f64, RowIterator), CrateDBError>
where SQL: Into<String>, S: Serialize;
fn bulk_query<SQL, S>(&self, sql: SQL, params: Box<S>)
-> Result<(f64, Vec<i64>), CrateDBError>
where SQL: Into<String>, S: Serialize;
}
Parameters are provided as a Box, which makes JSON serialization of arbitrary structs possible (thank you serde). Allowing arbitrary types with Rust’s very rigid type system (❤️) is difficult and sometimes requires a more hacky approach: although the query function has a parameter of type Option, it’s not possible to pass in None. This is due to None having an undefined type (it’s not a Box). In order to tell the compiler more about the type, the :: operator can be used to cast to a boxed type. Still, this is not enough, since the box needs a type that implements Serialize. As a solution the crate provides a type NoParams, so the user can do stuff like c.query("create blob table b", None::<Box<NoParams>>) to pass in a None with the expected type.
While the SQL interface is rather simple, the BLOB store requires more operations to get things done. The functions also translate directly to HTTP calls underneath (see also Backend), so it’s recommended to decouple the operation from time-sensitive code, especially put will create a SHA1 hash of the file contents which may take some time. On a side note: to reduce memory consumption (and have the ability to work with GiB scale files), rust-cratedb works with streams
pub trait BlobContainer {
fn list<TBL: Into<String>>(&self, table: TBL)
-> Result<Vec<BlobRef>, BlobError>;
fn put<TBL: Into<String>, B: Read + Seek>(&self, table: TBL, blob: &mut B)
-> Result<BlobRef, BlobError>;
fn delete(&self, blob: BlobRef)
-> Result<(), BlobError>;
fn get(&self, blob: &BlobRef)
-> Result<Box<Read>, BlobError>;
}
When a query is executed it runs synchronously which means that a call to these functions will block and return the server time (the f64 part of the tuple) along with the result only after the request was finished. Providing async variations of the API is planned 😉
Errors
Error handling is certainly one of the weaker points of the driver, mostly because there are several kinds of errors that should all somehow bubble up, but not panic, yet some are handled internally (e.g. connection errors via exponential backoff). However sometimes the underlying error classes do not translate too well, so that could be improved a lot.
Let’s examine situations where the driver should report Err() results:
- I/O from web requests or provided file streams
- Transport from in-transit web requests (and/or because the library uses this type)
- Parsers
- CrateDB’s errors
- HTTP statuses for BLOBs
This leads to situations where the request succeeds (no I/O errors occured, yet the HTTP status was - for example - 4xx, a status that, for a SQL statement, still requires the JSON parser to parse the response (but not for a BLOB operation). In order to not get lost in if/match cascades, it’s important to fail early and provide unwrapped variables for any following code.
To achieve some of these feats, an enum was the most practical approach:
#[derive(Debug, Clone)]
pub enum BlobError {
Action(CrateDBError),
Transport(BackendError),
}
While this still causes some cascades to be formed, they become much shorter and much more readable:
match self.backend
.fetch_blob(url, &blob.table, &blob.sha1)
.map_err(BlobError::Transport) { ... }
With this, any error could just be forwarded in the match clause.
Example
Now after all this explanation, take a look at the driver’s supposedly simple and coherent interface to connect to, store, and query data from CrateDB. Having had this goal in mind, the example to use the driver with an existing CrateDB instance is only a few lines of code:
extern crate cratedb;
use cratedb::{Cluster, NoParams};
use cratedb::sql::QueryRunner;
fn main() {
let c: Cluster = Cluster::from_string("http://localhost:4200");
let (elapsed, rows) =
c.query("select * from sys.cluster", None::<Box<NoParams>>)
.unwrap();
}
For more complex examples, please also look into the README.md, or the unit tests.
Roadmap
CrateDB is moving ahead and it’s important to keep up with some of the new (recent) features, especially regarding the Enterprise Edition that will add a few features around Authentication soon. Thus, here’s what’s coming to rust-cratedb soon:
- 1.1: Authentication, certificate support, better errors
- 1.2: Postgres Protocol support (Not quite sure on that yet)
- 2.0: Async API
Aside from that, there will be a driver for other sensors soon, and if there’s an opportunity - a meetup in Berlin 🤔
Thanks for reading! Please check out the Github repository, open issues, review code - anything is appreciated! Sharing the post on twitter is highly appreciated, too ❤️






