3 Ways To Get Closer To Your Customers
Become a local hero (of sorts) with Azure regions.

Do you have users around the globe? Have you ever worried about response times or local laws? A major advantage of any cloud provider is that this is usually easy to take care of - however is it worth the extra cost of closer to customers?
Commonly - and instinctively - everyone would agree that it makes the experience better. Making it economically viable however is a different story: can startups get into this early on or would the operating expense be too much of a risk? In addition to cost there is also complexity to manage: where to store the data? How to roll out updates?
Working at global scale
In a recent CSE engagement a customer was facing the decision of working on a global scale - with their customers having multiple regions to access the service with a desktop application. Consequently any latency issues will greatly affect the UX and potentially frustrate customers. With their service hosted on an Azure ServiceFabric cluster in Europe and the data stored in an Azure SQL database (also in Europe) - the question became how to provide the same high quality service to Australian customers?
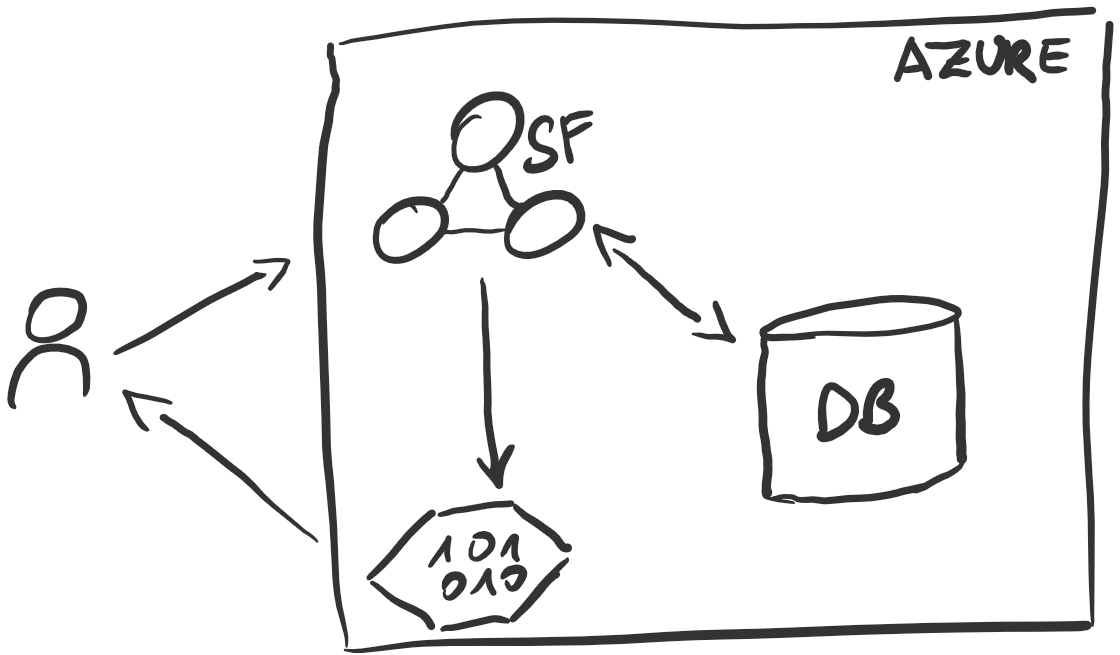
Anatomy of a service
The service itself is a series of RESTful endpoints and several storage accounts that offer BLOBs for the desktop application to download (the URLs will be provided in the responses). The whole thing looks like that:
Scenarios To Test
Due to the service’s distributed nature, the plan to migrate is straightforward: take each piece and move it from remote (i.e. the EU) to local (where the user is; Australia in this case) and check the results.
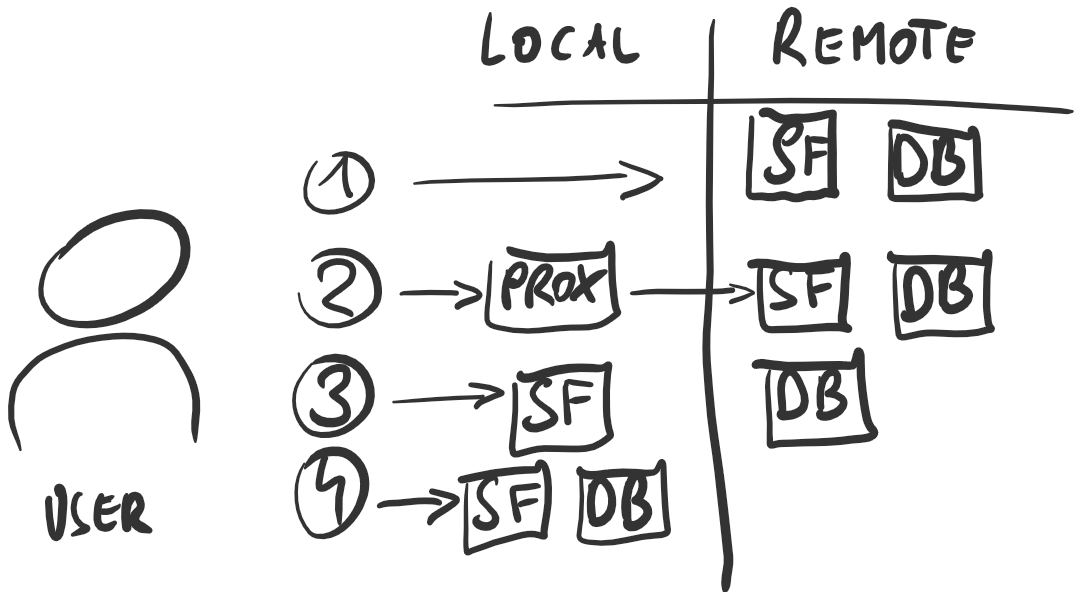
From this we can derive a total of four scenarios that should be looked at in order to get the data necessary for a well-founded decision. Benchmarking is hard and I would love to improve. There are (valid?) assumptions for all of the ways and tools used, please reach out on twitter if you have questions!
Tools
Tooling on Azure is plentyful, so it’s important to choose properly. Looking at Visual Studio Team Service’s load testing facilities, they offer to run tests from multiple locations! The perfect opportunity for experiencing service latencies from Australia and since these tests are run from within an Azure data center, they represent the absolute minimum latency to experience.
In a list form, here’s what we used:
- Visual Studio Team Services (VSTS) for running the tests
- Apache JMeter for creating the tests
- Jupyter for data analysis 😉
Getting a baseline …
Before starting off, we were keen on establishing a baseline. What was to be achieved? What is the current situation? For this, two main REST endpoints were identified and benchmarked, since these operations are vital to the user’s experience.
For now, these services will be called “Service A” and “Service B”.
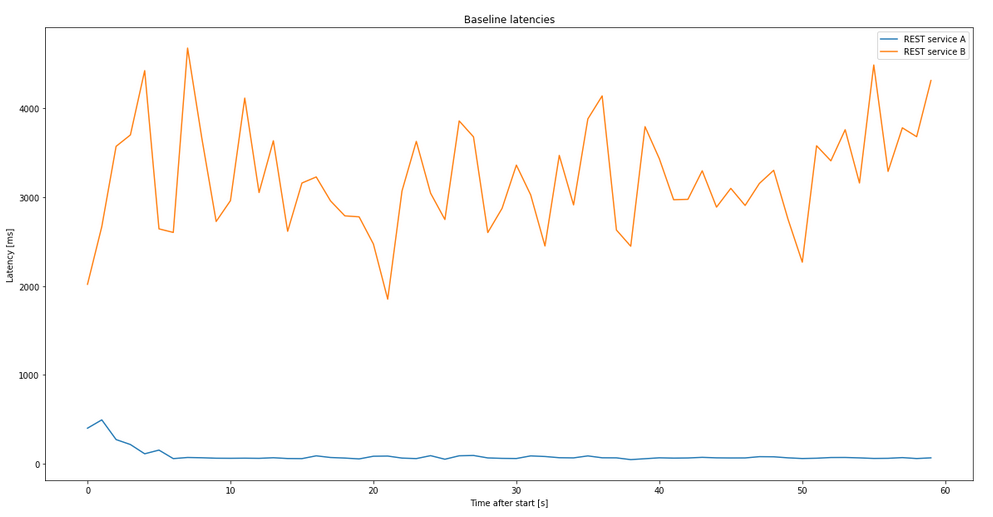
As obvious in this chart, the “Service B” was plagued by something during our tests, which is why the latency tests will focus on “Service A” for this post. Additionally, the gaps are due to the testing tool queuing up requests per thread. Hence a new request can only be sent once the previous returns which leads to gaps if all agents are busy waiting for a request …
… And Setting A Goal
Simply put, the goal is to get as close as possible to the baseline numbers - but in a controlled manner with economical decisionmaking and maintenance in mind! The current situation leaves a lot to be desired:
Let’s roll
In a few days the testing went from proxies to creating a switchable failover for the database in the target region (Australia), which puts everything there. The goal was to find the individual latencies and thereby evaluating potential strategies for the future!
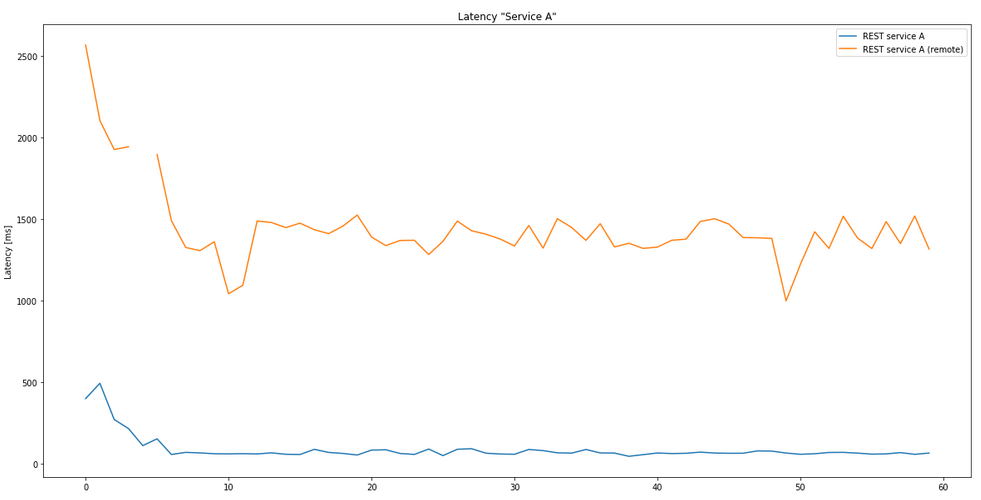
Solution 1: A simple proxy
As a potentially simple yet powerful solution we thought of deploying an API proxy within the desired region. They would work as an entrypoint into Microsoft’s backbone network and be faster just because of that - this was our hypothesis. Let’s see how it holds up versus the baseline!
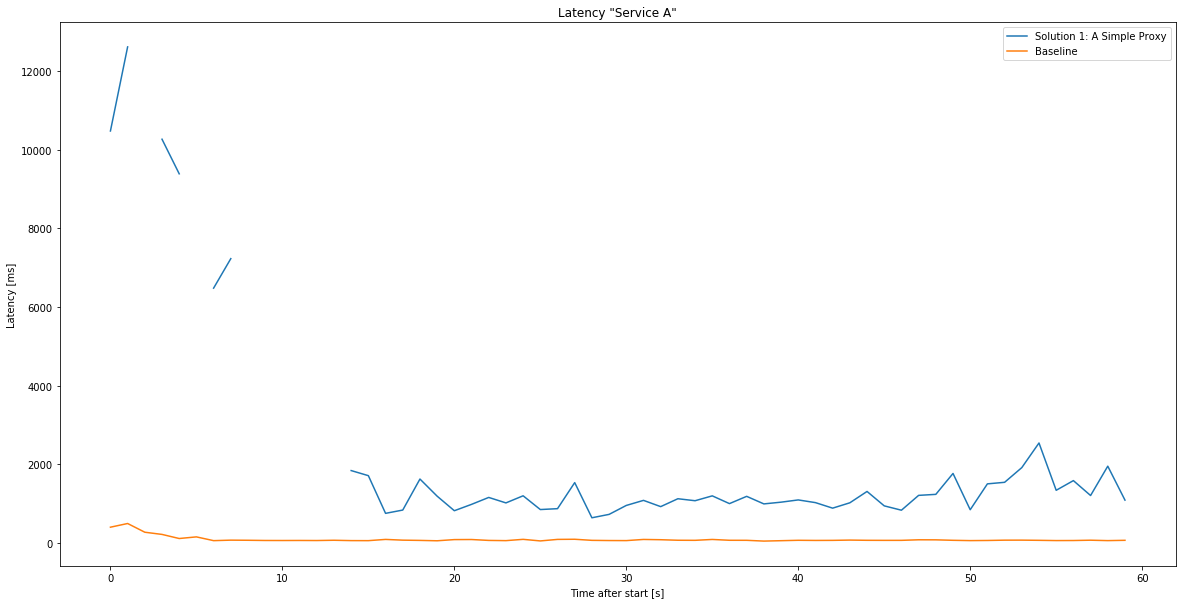
Upgrade: The cold start problem and auto scaling
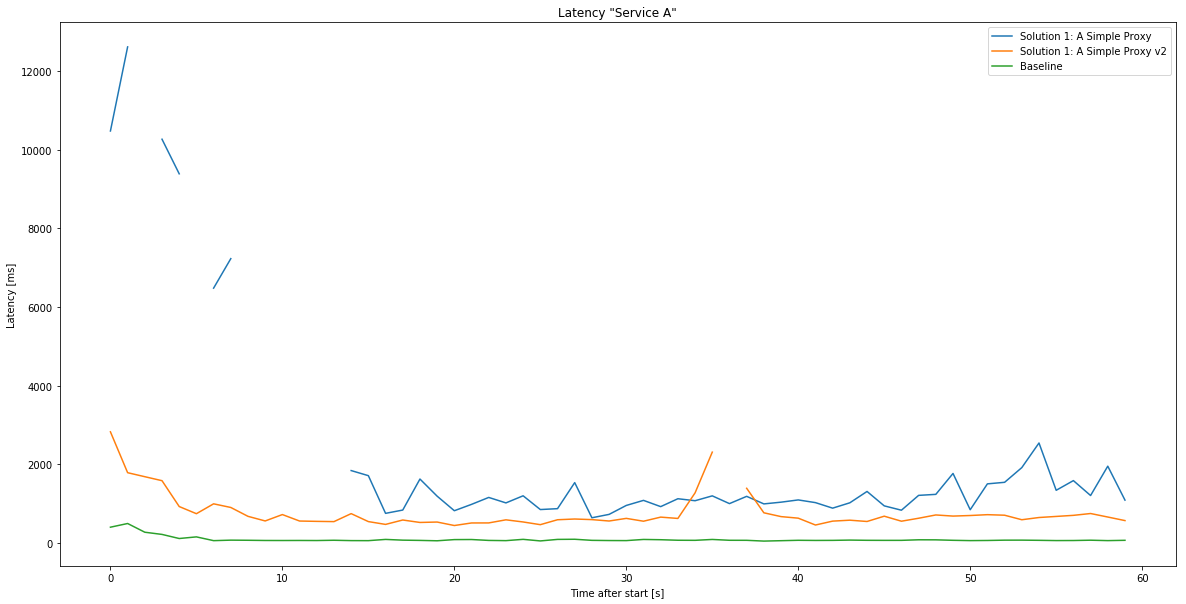
Looking at the chart above, the initial calls are somewhat slow and spikey - could this be due to the Function starting up or scaling up? Currently the best way to remedy that is to deploy the Function host on an AppService plan keeping them “hot” all the time. With that enabled, the chart looks like this:
Solution 2: A local cluster
If the application allows, it could make sense to move business logic closer to the consumer - this is especially useful if not every service has to hit the database (which would still be in the original location). Similar to the proxy setup, there’s some benefit of using Azure’s internal networking, but the main speedup will be the quicker response times when the business logic does not need a database.
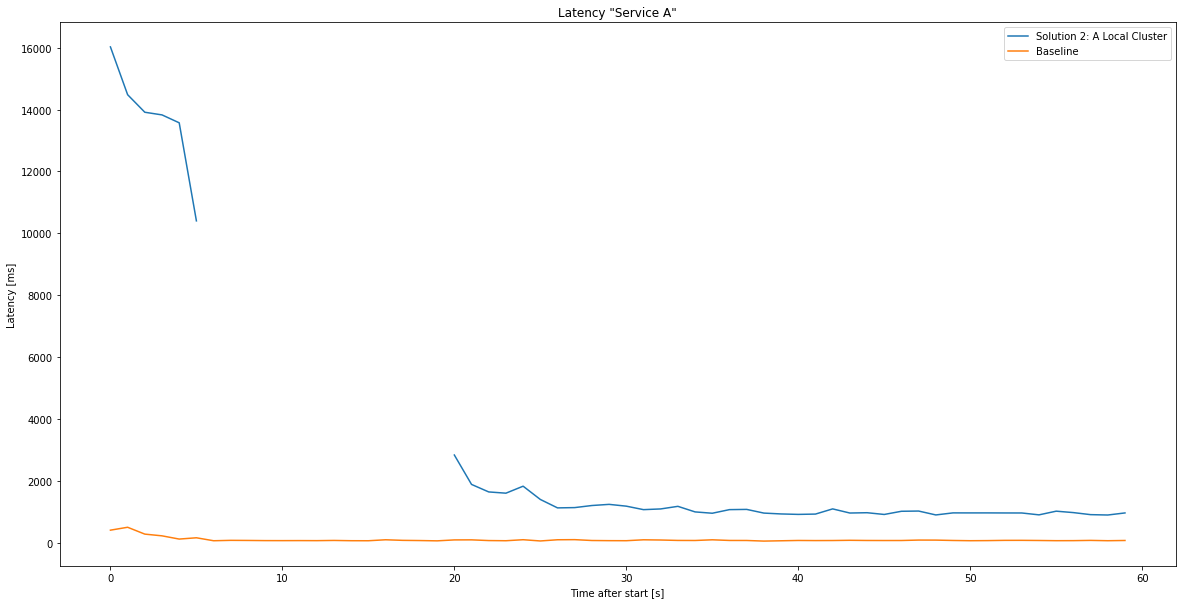
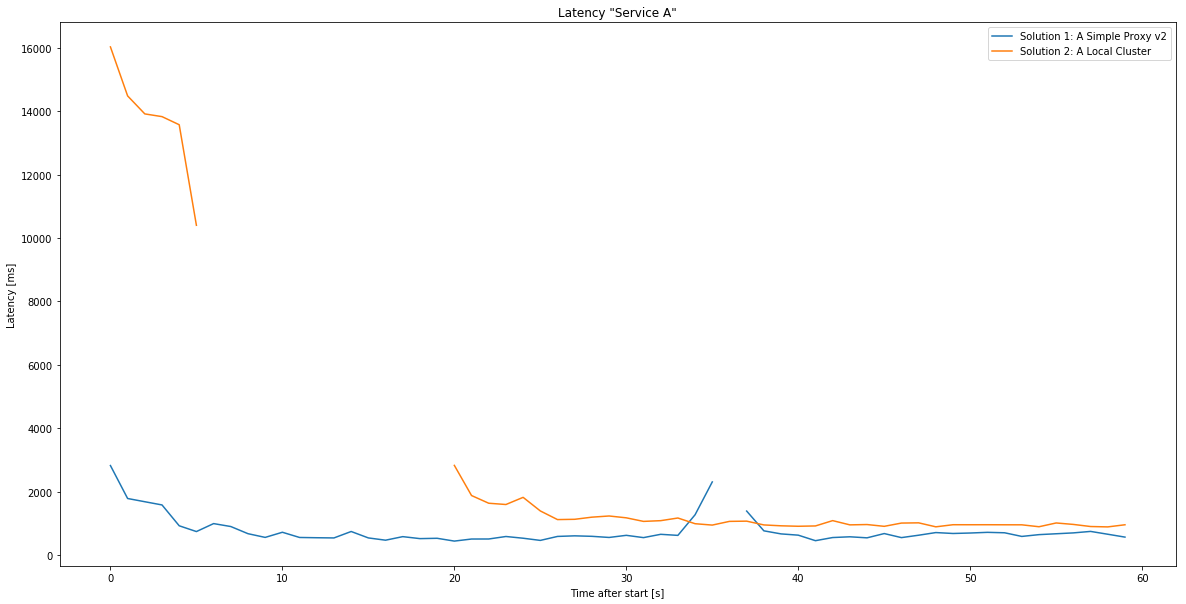
Curiously, the overhead of a local cluster seems to eat most of the benefits since - compared to the proxy - it doesn’t significantly outperform them! As a comparison, the latencies between the local cluster and a local (webapp) proxy:
Solution 3: A local cluster and database
Similar to solution 2, but going one step further! While the database was still in the original region (Europe) any communication between the business logic and the database could only use Azure’s internal networking. Imagine if a fairly simple select would always take about 200 ms to complete! Consequently we were using Azure SQL’s failover groups to replicate and then move the primary database to the local region.
Here’s how it went:
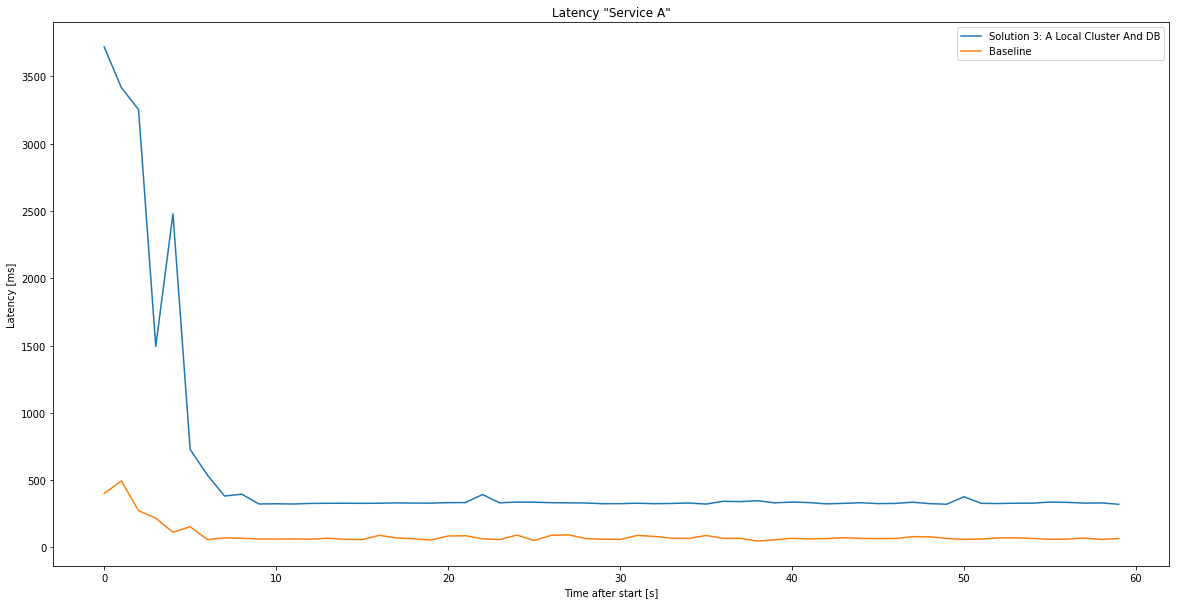
As expected the latencies are somewhat the same as the baseline, since there is no communication to the primary location required. However, this solution imposes the highest cost and maintenance (any European user in that tenant would have this very problem in reverse!).
What Should You Do?
To sum up, these are all latencies in a single chart:
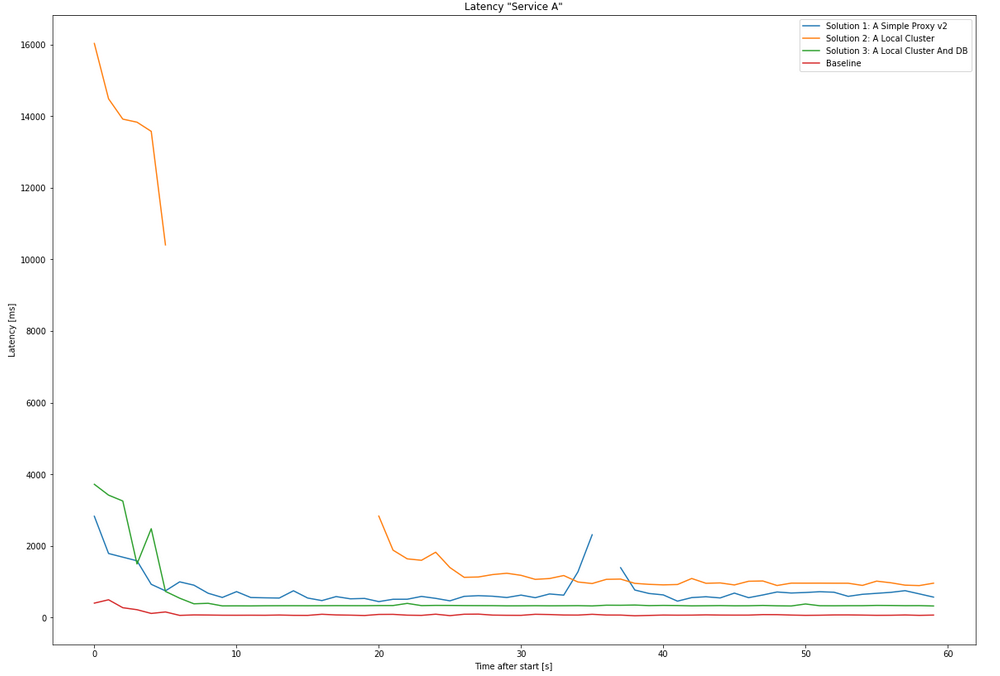
The results speak quite clearly: the baseline is close to 0 ms response time, after that, the local cluster including the database (Solution 3), then surprisingly a local proxy - and last creating a local cluster without the database. Although duplicating all infrastructure in the target region yields the best results (as expected), it comes with a significant cost. As a fan of incremental development and lean principles, the plan could be step-by-step when entering a new region:
- Create a functions based proxy for your API and local blob storage accounts.
- As demand increases use an AppService plan to keep latency low. Keep the storage accounts.
- Scale up as economically viable.
- When customer demand reaches a high enough level, move all parts into the target region.
Other than great response times, this approach can be employed to efficiently grow all over the world! Additionally the new regions can act as backup locations for existing customers and by using a database failover switch, any writeable parts can be changed to where demand comes from.
To read more stuff like this and the odd post about Rust projects subscribe via RSS (like feedly) and follow me on twitter.






