Finding the truth in online retail marketplaces
Using Bing search as a useful tool

A picture I took near the customer’s office in Bordeaux, FR: Pont Jacques Chaban-Delmas
This post is about the work I do at Microsoft, read more here.
Online retail platforms are strange places, valid information is rare and especially titles seem to be the catch-all. Partly of course, this is encouraged by the platform for SEO reasons and while this is only a slight annoyance for consumers, platform providers struggle a lot more: their goal is to gather structured data about the products (e.g. to improve comparability, search relevance etc.). The seller however strifes for visibility and that often does not go hand in hand.
Did you ever think about how companies do this? How companies allow millions of arbitrary products and still provide facts about size, weight etc? I certainly did not and I was very surprised about the challenges they face!
What to even look for?!
The first obstacle was quickly encountered: how to uniquely identify the product (and by extent its manufacturer)? Companies sometimes use different product names for import/export or exchange components to conform with local laws (supported LTE frequencies are a good example) and technical specifications can be entirely different, yet the product name only has an additional ‘i’ at the end… Rather where to look, the question quickly becomes: what is this?!
How do companies go about this then? In the case of our customer they built a huge pipeline that automatically finds multiple descriptions on the internet and runs page-long regular expressions with a human double check the end result.
Online Retail & us
This story is about a week-long engagement with one of our customers to remedy this problem. During this engagement, two small teams tackled the problem from both ends: I was part of the search team (with two others), my colleagues were tackling the property extraction aspect using machine learning. Here’s what the goals of search were:
- Find at least two websites to fill in specified (product) properties
- Retrieve the content of these websites in a usable format
- Minimize the risk that the retrieved text is irrelevant or misleading
Specifically out of the scope of this part of the engagement is:
- Extracting new/unknown property values
- Finding specific trustworthy sources
Metrics
Any sort of search on unknown data yields an enourmous amount of results that cannot be hand-checked. Therefore the checking has to be done via more abstract measures to provide a form of feedback on the tasks. Since the entire pipeline is based a lot around improving confidence by having more data (e.g. truth can then be found by majority voting on the value of a product property), a few simple metrics can be derived:
- Volume, i.e. at least two domains have to be returned from the search
- Simple “contains” search - do the results actually contain the full search term?
These two basic metrics let me iterate quickly (it took hours to run their RegExs) and provide a best guess on the lower bounds of the actual result count.
Bing Search to the rescue
Within the cognitive services API collection, there are several web services with different objectives. The Bing search API provides a programmatic interface to the search engine at bing.com, a more general approach to finding the required data all over the internet, compared to Bing custom search, which requires a list of websites to be searched. The two approaches are essentially a blacklisting (Bing classic) vs whitelisting (Bing custom) problem - this blog post focusses on Bing classic.
Creating a Query
The core part of finding the data is generating a query with Bing’s search syntax to maximize precision. The goal is to strike a balance between a too narrow query (i.e. it requires too many conditions and therefore reduces the result set considerably) and returning too many comparison/SEO optimized pages. By the end of the hack week the pattern was as follows:
((<product name>) AND ("<property name>")) <sites to limit the search to (if applicable)> <excluded sites> NOT filetype:xls NOT filetype:pdf NOT filetype:doc NOT filetype:docx NOT filetype:pptx
After experiments with different variations with quoted strings (literal matches), the version above turned out to be the most effective combination so far. The inclusion clauses allows for specific sites to be searched exclusively (e.g. amazon.com), whereas the exclusion clause will remove the customer’s site from the result set (and other SEO optimized sites like pinterest.com) by default. Since the text extraction libraries also cannot handle filetypes other than text, a few simple “NOT” clauses remove those as well.
Bing can also only search in specific languages and markets. since language might reduce the result set too much and the product and property names were in the target language anyway, the application targets a specific market (’en-US’ by default).
How to find the essential parts
In order to reduce SEO efforts and minimize re-using the same source twice, a search returns 60 results, which are then aggregated by their domains. With the following snippet, only the first result of each domain is returned. As a consequence the first two results will be from two different domains, increasing the robustness of the property value when found in both.
.then((w) => { // w for webResult
let actualSites = [...new Set(w
.map((site) => url.parse(site["url"]).host))];
return actualSites
.map((s) => w.find((p) => p["url"].includes(s)) // find returns the first match
);
})
In order to remove any ads, analytics, SEO or other irrelevant content, the website data needs to be processed by either a library like node-unfluff but due to its limited support for languages other than English, we chose the OneNote Web Clipper API to do the trimming. A later version of the tool should definitely include a machine learning model to “unfluff” the particular market’s language!
Unleash!
Having established a RESTful endpoint that delivers the expected content, it’s now time to scale. With each request resulting in two subsequent web requests (one to Bing, one to a content extraction service) a search will take seconds with lots of waiting. Hence this would be perfect for something like Kubernetes to work with. Running 20-30 containers (or more) in parallel with the load balancer taking care of request distribution, a script can easily go through some 5 000 products in a reasonable time.
First, a container is required:
FROM mhart/alpine-node:9.4
RUN mkdir /app
COPY package.json /app/package.json
COPY app.ts tsconfig.json /app/
COPY routes /app/routes
COPY services /app/services
COPY views /app/views
COPY bin /app/bin
RUN cd /app && npm install && /app/node_modules/typescript/bin/tsc
WORKDIR /app
CMD ["node", "/app/out/bin/www.js"]
After building, the container is stored in a repository (in this case Azure Container Registry) and pushed to Microsoft’s managed Kubernetes service (Azure Container Service - AKS) using a deployment config like this:
apiVersion: v1
kind: Service
metadata:
name: clipper-service
spec:
type: LoadBalancer
ports:
- port: 3000
selector:
app: clipper
---
apiVersion: apps/v1beta2
kind: Deployment
metadata:
name: clipper-deployment
spec:
replicas: 3
selector:
matchLabels:
app: clipper
template:
metadata:
labels:
app: clipper
spec:
imagePullSecrets:
- name: registrykey
containers:
- image: cmacr.azurecr.io/cd/clipper:latest
name: clipper
ports:
- containerPort: 3000
env:
- name: CLIPPER_API_URL
value: "https://www.onenote.com/onaugmentation/clipperextract/v1.0/?renderMethod=extractAggressive&url=%s"
- name: BING_SEARCH_KEY
value: "<my-key>"
- name: MICROSOFT_TRANSLATION_API_URL
value: "https://api.microsofttranslator.com/v2/Http.svc"
- name: MICROSOFT_TRANSLATION_API_KEY
value: "<my-other-key>"
Starting out with only three replicas, one can quickly scale up to dozens of containers!
Amazon Mechanical Turk
Many companies use MTurk for these small tasks - I certainly have identified my share of matresses there 😅. However, two of the main problems are: the language and accuracy. It was definitely considered by our customer, but did not deliver the expected results!
Results & Known issues
By the end of the customer engagement we achieved a major increase in their available data and prelimiary tests showed that many of the missing properties can now be filled. The company translated this directly in an increase of product data quality using a custom KPI calculation (based on how filling in product properties increase sales numbers - because they can now be found easier). Since we agreed on providing more data for 2% of product properties where they did not have data before to consider the engagement a success, we were quite happy to hear that our combined effort resulted in an increase of at least 2%. The specifics are of course up for debate by their BI department 😊
While working on increasing the raw data for their pipeline to work on we had our own learnings as well:
- Unfortunately we were only able to evaluate the search results on the very last day. A feedback loop during the event would have increased the quality further!
- Extracting relevant content from websites is a challenge in its own right. Fetching the site and extracting the content (vs ads, analytics, SEO efforts, UX fluff) requires a language specific, well trained model. For now the OneNote Web Clipper does the extraction.
- Translating the search terms and searching them in Bing’s largest “market” - the US - did not improve results.
- Limiting the sites to a few “trusted” sources is not always better. In fact the results were worse for our stats than searching the entire market.
- Query expansion for property names could improve confidence while even increasing the information pool.
A completely different approach would be to curate your own database of products (which could be scraped from the web) in order to tweak the indexing part with custom fields, aggregations, etc. I can recommend CrateDB 😅. (Disclaimer: I worked there)
Thank you for reading, I hope I could shed some insights into how search works to create better products and enable customers to create interesting applications! 💖
More of this type of content? Less? Please let me know on Twitter, so I can adjust accordingly
💡 Stats & numbers ahead!
Appendix: Numbers, graphs & stats
Lines of code in the project (includes an implementation of Bing search and custom search):
--------------------------------------------------------------------------------
Language Files Lines Blank Comment Code
--------------------------------------------------------------------------------
JSON 3 5253 0 0 5253
TypeScript 24 2363 511 227 1625
Python 1 118 22 4 92
Bourne Shell 2 111 35 23 53
YAML 1 58 1 10 47
JavaScript 1 11 1 0 10
CSS 1 8 1 0 7
--------------------------------------------------------------------------------
Total 33 7922 571 264 7087
--------------------------------------------------------------------------------
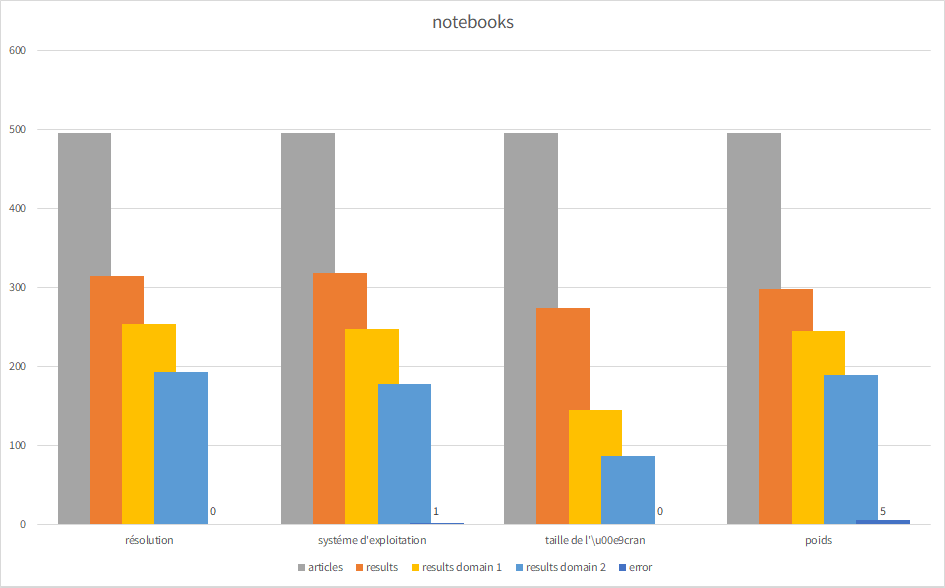
Furthermore, here are some insights into the Bing search results. The “market” was set to fr-FR, so the results and the search query were French (from France). The test sample were 11 properties for ~ 500 products in 3 different categories: phones, tablets, and notebooks (the highest grossing products for our customer).
For each search these are the numbers displayed:
- articles: the number of articles searched
- error: how many errors occured (anywhere in the workflow)
- results domain 1: a quick check if the search term appears in the first domain result
- results domain 2: a second check if the search term appears in the second domain result
As a quick summary, here are the average number of articles, how many of those were found on Bing, and how many of those have the search term appear in the first two domains of the results (and therefore gained a higher confidence).
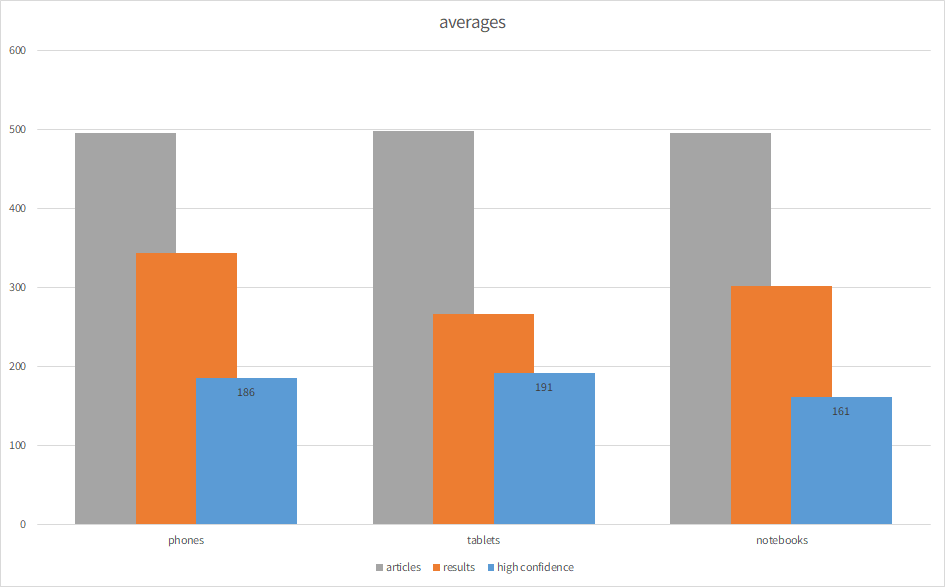
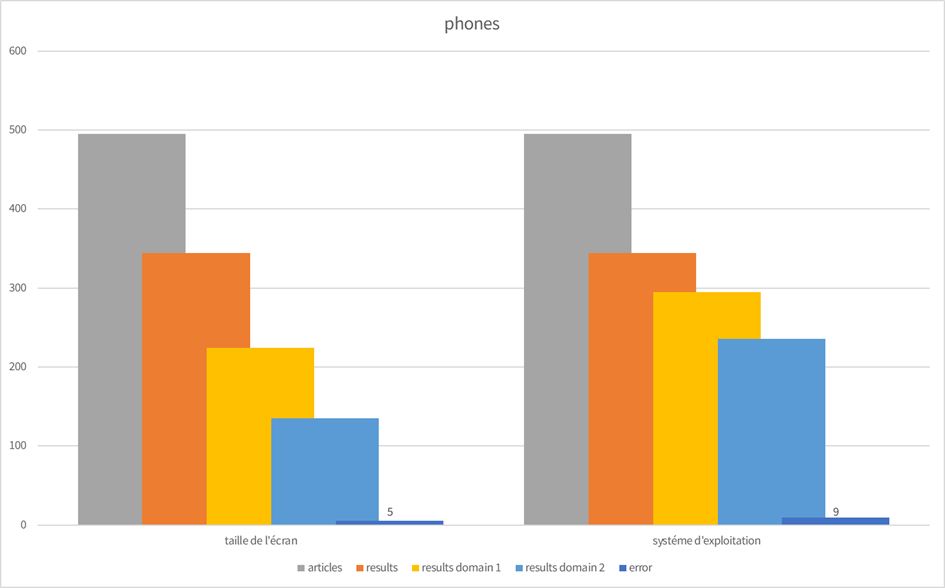
Check out the details for each category below…
Phones
| taille de l’écran | systéme d’exploitation | |||
|---|---|---|---|---|
| articles | 495 | 495 | ||
| error | 5 | 9 | ||
| results | 344 | 344 | ||
| results domain 1 | 224 | 295 | ||
| results domain 2 | 135 | 236 |
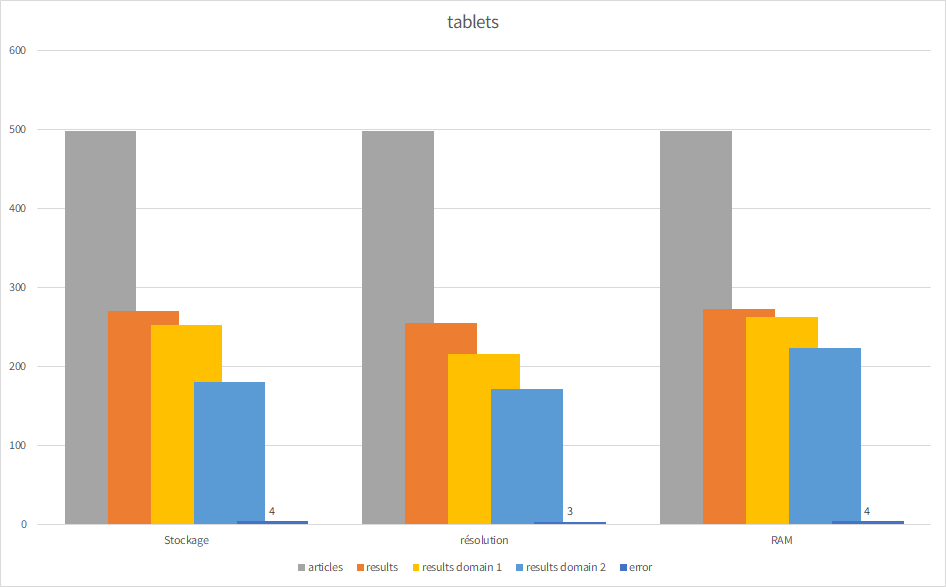
Tablets
| taille de l’écran | systéme d’exploitation | |||
|---|---|---|---|---|
| articles | 498 | 498 | 498 | |
| error | 4 | 3 | 4 | |
| results | 270 | 255 | 272 | |
| results domain 1 | 252 | 216 | 262 | |
| results domain 2 | 180 | 171 | 223 |
Notebooks
| taille de l’écran | systéme d’exploitation | |||
|---|---|---|---|---|
| articles | 495 | 495 | 495 | 495 |
| error | 0 | 1 | 0 | 5 |
| results | 314 | 318 | 274 | 298 |
| results domain 1 | 254 | 247 | 145 | 244 |
| results domain 2 | 193 | 177 | 86 | 189 |